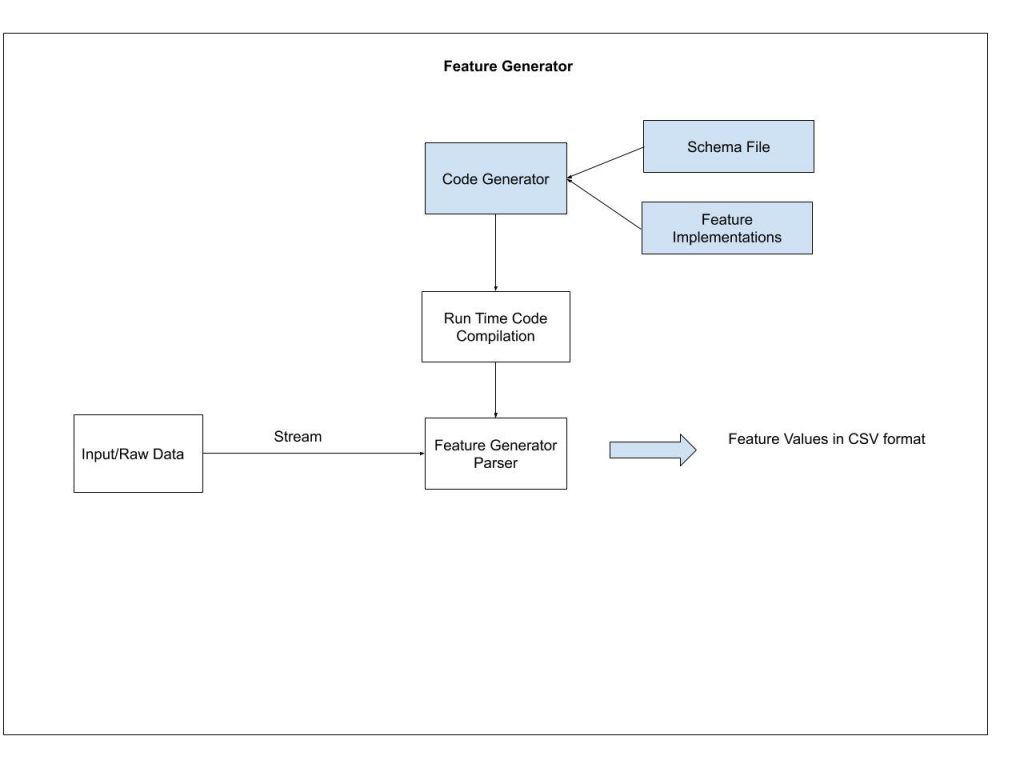
Feature Generation is the fodder for ML models. Without robust features, a ML model is useless.
Having a clean, easy and verifiable way to generate features with small data set and able to scale the same to huge data and/or using big data systems as Hive or Spark is essential to move fast in changing environment.
Feature generation is the place where data scientists and data engineers meet. So it should be simple enough for non coders to be effectively participate but robust enough to be used in engineering process. So it is essential to separate the feature definitions from feature implementations.
One of the way to generate features is to have a clear name/value view of the features and how features are getting computed. Eg:-
FeatureName1 CalculateValue(UsingSomeData)
This type of structure separates the definitions and the implementations of feature. The feature definition file (the schema file) can be used for wider audience to determine the composition of a given model.
I used the Python language inbuilt parser to accomplish this type of feature generation. Recently, I put one such simple implementation in public GitHub as a reference.
The ability to generate code and parse it during runtime is available in almost all language. I am sure this concept can be ported to any programming language.
Food for thought
- How to compute aggregate features
- How to reuse feature values already computed earlier and only compute and prepend the new feature values
- How will the feature generation design change for time series data.